Investigadores proponen un modelo nuevo y más eficiente para el reconocimiento automático de voz
 utilise l'apprentissage du") Investigación de inteligencia artificial CAAIPrensa de la Universidad de Tsinghua” width=”800″ height=”463″/>
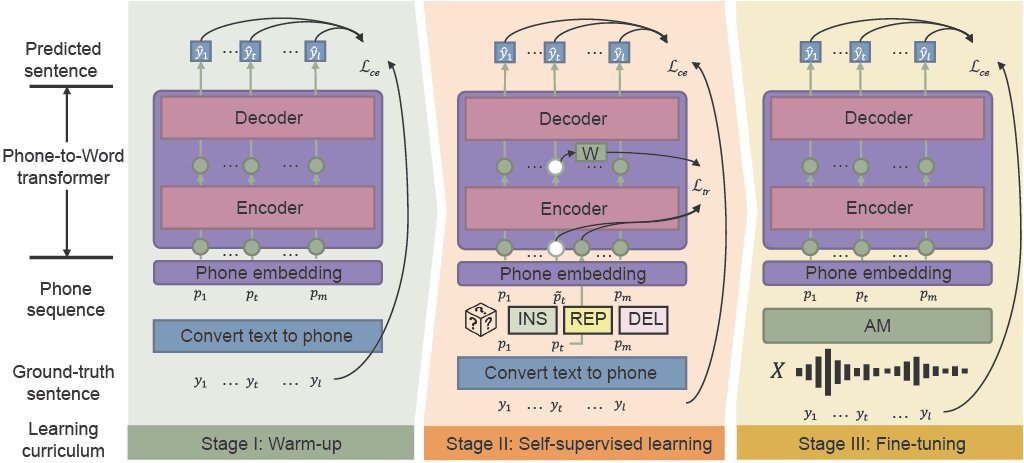
Investigación de inteligencia artificial CAAIPrensa de la Universidad de Tsinghua” width=”800″ height=”463″/> El marco de Pre-Entrenamiento Fonético-Semántico (PSP) utiliza el aprendizaje de “programa consciente del ruido” para mejorar efectivamente el rendimiento de ASR en entornos ruidosos. integrando el calentamiento, el aprendizaje autosupervisado y el ajuste fino. Crédito: CAAI Investigación en Inteligencia ArtificialPrensa de la Universidad de Tsinghua
Asistentes de voz populares como Siri y Amazon Alexa han introducido el reconocimiento automático de voz (ASR) a las masas. A pesar de décadas de fabricación, los modelos ASR luchan por ser consistentes y confiables, especialmente en entornos ruidosos. Investigadores chinos han desarrollado un marco que mejora efectivamente el rendimiento de ASR para el caos de los entornos acústicos cotidianos.
Investigadores de la Universidad de Ciencia y Tecnología de Hong Kong y WeBank propusieron un nuevo marco de preentrenamiento fonético-semántico (PSP) y demostraron la solidez de su nuevo modelo frente a conjuntos de datos sintéticos muy ruidosos.
Su estudio fue publicado en CAAI Investigación en Inteligencia Artificial 28 de agosto.
“La robustez ha sido un desafío de larga data para ASR”, dijo Xueyang Wu del Departamento de Ciencias de la Computación e Ingeniería de la Universidad de Ciencia y Tecnología de Hong Kong. “Queremos aumentar la solidez del sistema ASR chino a un costo menor”.
usos ASR aprendizaje automático y otras técnicas de inteligencia artificial para traducir automáticamente el habla en texto para usos como sistemas activados por voz y software de transcripción. Pero las nuevas aplicaciones centradas en el consumidor exigen cada vez más que el reconocimiento de voz funcione mejor, maneje más idiomas y acentos, y funcione de manera más confiable en situaciones del mundo real, como videoconferencias y entrevistas en vivo.
Tradicionalmente, entrenar los modelos acústicos y lingüísticos que componen ASR requiere grandes cantidades de datos específicos del ruido, lo que puede llevar mucho tiempo y ser costoso.
El modelo acústico (AM) transforma las palabras en “fonos”, que son secuencias de sonidos básicos. El modelo de lenguaje (LM) decodifica los teléfonos en oraciones de lenguaje natural, generalmente con un proceso de dos pasos: un LM rápido pero relativamente débil genera un conjunto de oraciones candidatas, y un LM potente pero computacionalmente costoso selecciona la mejor oración entre los candidatos.
“Los modelos de aprendizaje tradicionales no son robustos contra las salidas ruidosas del modelo acústico, especialmente para las palabras polifónicas chinas con pronunciación idéntica”, dijo Wu. “Si la primera pasada de la decodificación del modelo de aprendizaje es incorrecta, es extremadamente difícil que la segunda pasada se ponga al día. .”
El marco PSP recientemente propuesto facilita la recuperación de palabras mal clasificadas. Al entrenar previamente un modelo que traduce las salidas de AM directamente en oraciones con información contextual completa, los investigadores pueden ayudar a LM a recuperarse de manera eficiente de las ruidosas salidas de AM.
El marco PSP permite que el modelo mejore a través de un régimen de entrenamiento previo llamado Programa Sensible al Ruido que gradualmente introduce nuevas habilidades, comenzando de manera fácil y progresando gradualmente hacia tareas más complejas.
“La parte más crucial de nuestro método propuesto, el aprendizaje del plan de estudios consciente del ruido, simula el mecanismo por el cual los humanos reconocen una oración del habla en voz alta”, dijo Wu.
El calentamiento es el primer paso, donde los investigadores entrenan previamente un transductor de teléfono a palabra en una secuencia de teléfono limpia, que se traduce solo a partir de datos de texto sin etiquetar, para reducir el tiempo de anotación. Este paso “calienta” el modelo, inicializando los parámetros básicos para mapear secuencias telefónicas a palabras.
En la segunda etapa, aprendizaje autosupervisado, el transductor aprende de datos más complejos generados por técnicas y funciones de aprendizaje autosupervisado. Finalmente, el transductor de teléfono a palabra resultante se refina con datos de voz del mundo real.
Los investigadores demostraron experimentalmente la efectividad de su marco en dos conjuntos de datos reales recopilados de escenarios industriales y ruido sintético. Los resultados mostraron que PSP cuadro Mejora de manera efectiva la canalización ASR tradicional, reduciendo las tasas de error relativo de caracteres en un 28,63 % para el primer conjunto de datos y en un 26,38 % para el segundo.
En los próximos pasos, los investigadores investigarán métodos de preentrenamiento de PSP más eficientes con conjuntos de datos no emparejados más grandes, buscando maximizar la eficiencia del preentrenamiento para el LM resistente al ruido.
Xueyang Wu et al, Un modelo de preentrenamiento fonético-semántico para un reconocimiento de voz robusto, CAAI Investigación en Inteligencia Artificial (2022). DOI: 10.26599/AIR.2022.9150001
Proporcionado por Prensa de la Universidad de Tsinghua
Cotizar: Los investigadores proponen un modelo nuevo y más eficiente para el reconocimiento automático de voz (2 de septiembre de 2022) Consultado el 2 de septiembre de 2022 en https://techxplore.com/news/2022-09-effect-automatic-speech-recognition.html
Este documento está sujeto a derechos de autor. Excepto para el uso justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin permiso por escrito. El contenido se proporciona únicamente a título informativo.

“Adicto a la televisión total. Experto en viajes. Gurú de Twitter. Evangelista de tocino. Creador galardonado. Aficionado al alcohol. Fanático de la música. Solucionador de problemas”.

